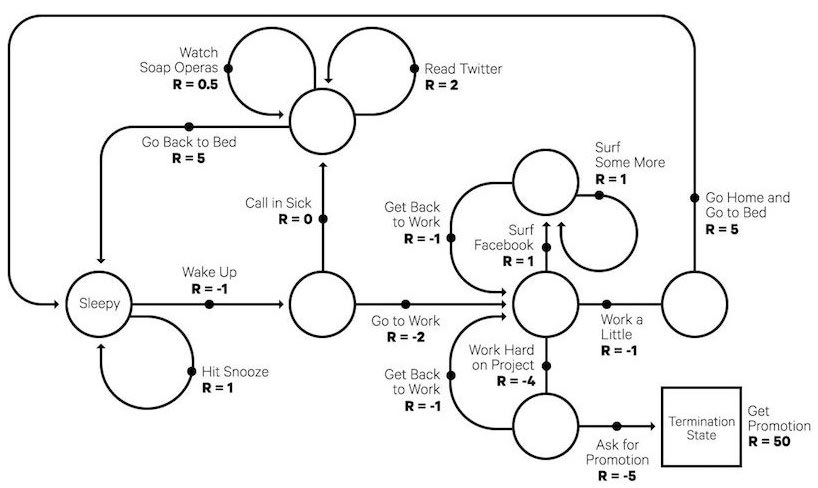
به بیان رسمیتر، تقریباً تمام مسائل RL را میتوان به عنوان فرآیندهای تصمیم گیری مارکوف (MDP) در نظر گرفت. تمام حالتها در MDP دارای ویژگی "مارکوف" هستند،
به بیان رسمیتر، تقریباً تمام مسائل RL را میتوان به عنوان فرآیندهای تصمیم گیری مارکوف (MDP) در نظر گرفت. تمام حالتها در MDP دارای ویژگی "مارکوف" هستند، با اشاره به این واقعیت که آینده فقط به وضعیت فعلی بستگی دارد، نه گذشته:P[St+1|St]=P[St+1|S1,…,St]P[St+1|St]=P[St+1|S1,…,S
یا به عبارت دیگر، آینده و گذشته با توجه به زمان حال به طور مشروط مستقل هستند ، زیرا وضعیت فعلی تمام آماری را که برای تصمیم گیری در مورد آینده نیاز داریم در بر میگیرد.
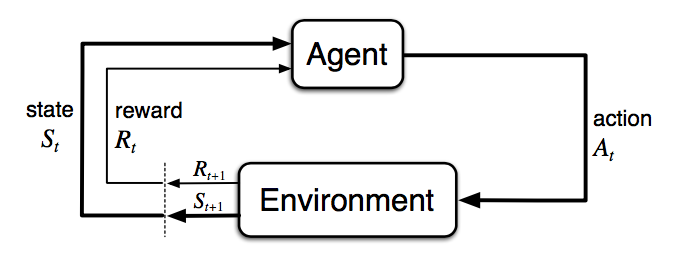
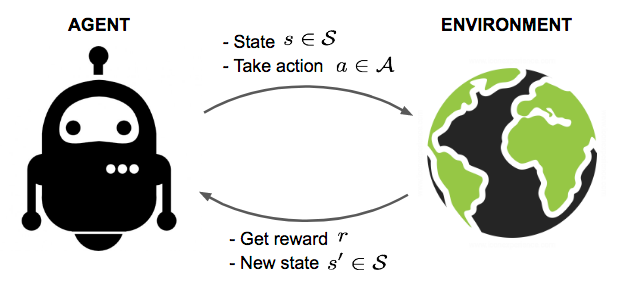
شکل ۳. تعامل عامل-محیط در فرآیند تصمیم گیری مارکوف. (منبع تصویر: Sec. 3.1 Sutton & Barto (2017).)
فرآیند تصمیم گیری مارکف از پنج عنصر تشکیل شده است
M=⟨S,A,P,R,γ⟩
که در آن نمادها همان مفاهیم کلیدی در بخش قبل را دارند و به خوبی با تنظیمات مشکل RL همسو می شوند:
SSS مجموعه ای از حالات
AAA مجموعه ای از اقدامات
PPP تابع احتمال انتقال
γ عامل تخفیف برای پاداش های آینده. در یک محیط ناشناخته، ما دانش کاملی در مورد P و R آن نداریم
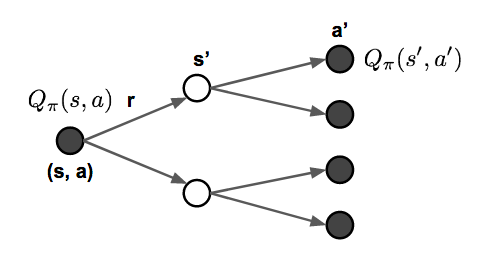
فرآیند بهروزرسانی بازگشتی را میتوان بیشتر تجزیه کرد تا معادلاتی باشد که بر روی هر دو توابع حالت-مقدار و اقدام-مقدار ساخته شدهاند. همانطور که در مراحل اقدام آینده پیش می رویم، V و Q را به طور متناوب با پیروی از خط مشی πππQ∗ گسترش میدهیم
شکل ۵. تصویری از چگونگی بروزرسانی معادلات انتظار بلمن توابع حالت-مقدار و اقدام-مقدار
اگر ما فقط به مقادیر بهینه علاقهمند باشیم، به جای محاسبه انتظارات منتج از یک خط مشی، میتوانیم بدون استفاده از یک خط مشی، در طول بروزرسانیهای جایگزین، مستقیماً به حداکثر بازده بپردازیم. به طور خلاصه: مقادیر بهینه V ∗ و Q ∗ بهترین بازدههایی هستند که میتوانیم به دست آوریم، که در اینجا تعریف شدهاند.
جای تعجب نیست که آنها بسیار شبیه معادلات انتظار بلمن هستند.
اگر اطلاعات کاملی از محیط داشته باشیم، به یک مشکل برنامهریزی تبدیل میشود که توسط DP قابل حل است. متأسفانه، در اکثر سناریوها، ما Pass′ یا R(s,a)R(s,a)R(s,a) نمیدانیم
بنابراین ما نمیتوانیم MDPها را با استفاده مستقیم از معادلات بلمن حل کنیم، اما پایهی نظری بسیاری از الگوریتمهای RL را میگذارد.